ViBe: A Text-to-Video Benchmark for Evaluating Hallucination in Large Multimodal Models
Pytorch, Hugging Face
ViBe has been accepted as a NAACL'25 Workshop paper at TrustNLP'25 !
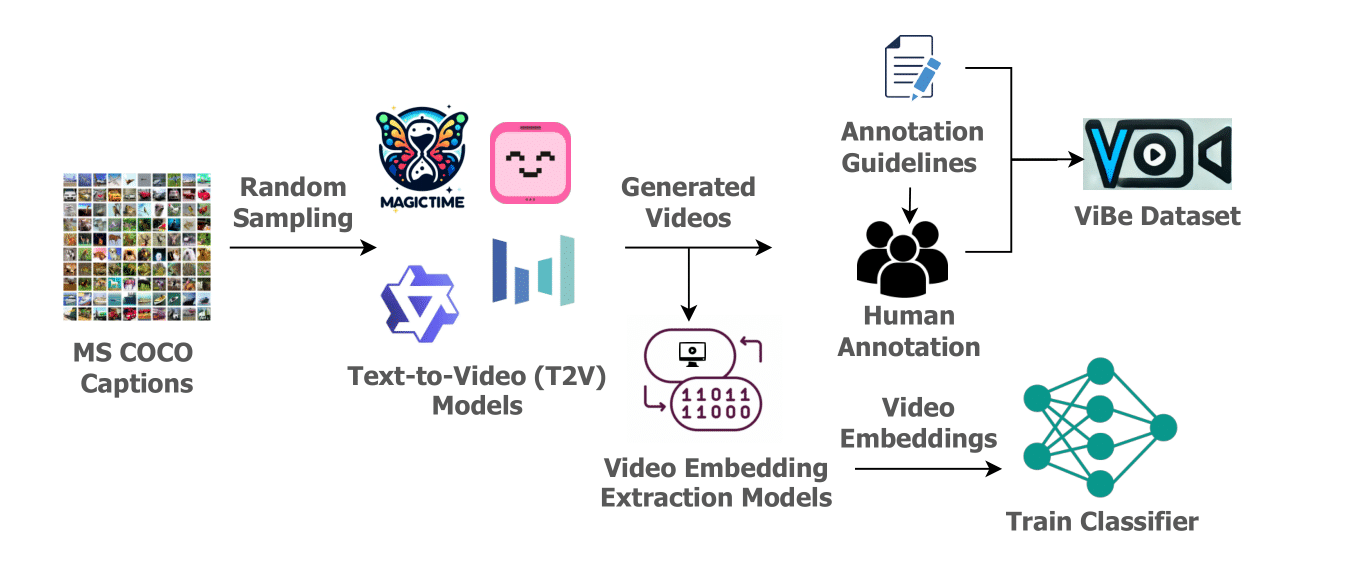
ViBe offers a unique resource for evaluating the reliability of T2V models and provides a foundation for improving hallucination detection and mitigation in video generation. We establish classification as a baseline and present various ensemble classifier configurations, with the TimeSFormer + CNN combination yielding the best performance, achieving 0.345 accuracy and 0.342 F1 score. This benchmark aims to drive the development of robust T2V models that produce videos more accurately aligned with input prompts.